한국데이터산업진흥원 게시자료에 기반한 요약 정리
1과목 50문제 중 10문제 출제
과락 할 확률 높음
개념 위주 출제
1과목 - 데이터 모델링의 이해
제2장 데이터 모델과 성능

1절 성능 데이터 모델링의 개요
성능 데이터 모델링
데이터베이스 성능 향상을 목적으로 설계단계의 데이터 모델링 때부터, 성능과 관련된 사항이 데이터 모델링에 반영되도록 하는 것
성능 데이터 모델링 수행 시점
분석/설계 단계,
성능 데이터 모델링 시점이 늦어질수록 재업무 비용이 증가
성능 데이터 모델링 고려 사항
정규화 수행,
데이터베이스 용량 산정과 트랜잭션 유형 파악을 통한 반정규화 수행, 정규화는 무조건 해야 됨
📌 성능을 고려한 데이터모델링 순서 ⭐⭐
1. 데이터 모델링을 할 때 정규화를 정확하게 수행
2. 데이터베이스 용량 산정 수행
3. 데이터베이스에 발생되는 트랜잭션 유형 파악
4. 용량과 트랜잭션의 유형에 따라 ㅛ 수행
5. 이력모델의 조정, PK/FK 조정, 슈퍼타입/서브타입 조정 수행
6. 성능관점에서 데이터 모델 검증
2절. 정규화와 성능
정규화(Normalization)
데이터 분해 과정, 이상현상(anomaly) 제거
정규형(NF; Normal Form)
정규화로 도출된 데이터 모델이 갖춰야 할 특성
- 함수적 종속성(FD; Functional Dependency)
결정자와 종속자의 관계,
결정자의 값으로 종속자의 값을 알 수 있다.
- 다치 종속(MVD; Multivalued Dependency)
여러 칼럼이 동일한 결정자의 종속자일 때
🔍 정규화 이론 ⭐
- 1차 2차 3차 보이스코드 정규화는 함수적 종속성에 근거
- 4차 정규화는 다치 종속을 제거
- 5차 정규화는 조인에 의한 이상현상을 제거하여 정규화를 수행함
1. 1차 정규화
속성의 원자성 확보,
다중값 속성을 분리함
2. 2차 정규화
부분 함수 종속성 제거,
일부 기본키에만 종속된 속성을 분리함,
기본키가 하나의 칼럼일 때 생략 가능

부분 함수 종속성
3. 3차 정규화
이행 함수 종속성 제거,
서로 종속관계가 있는 일반속성을 분리함,
주식별자와 관련성이 가장 낮다.
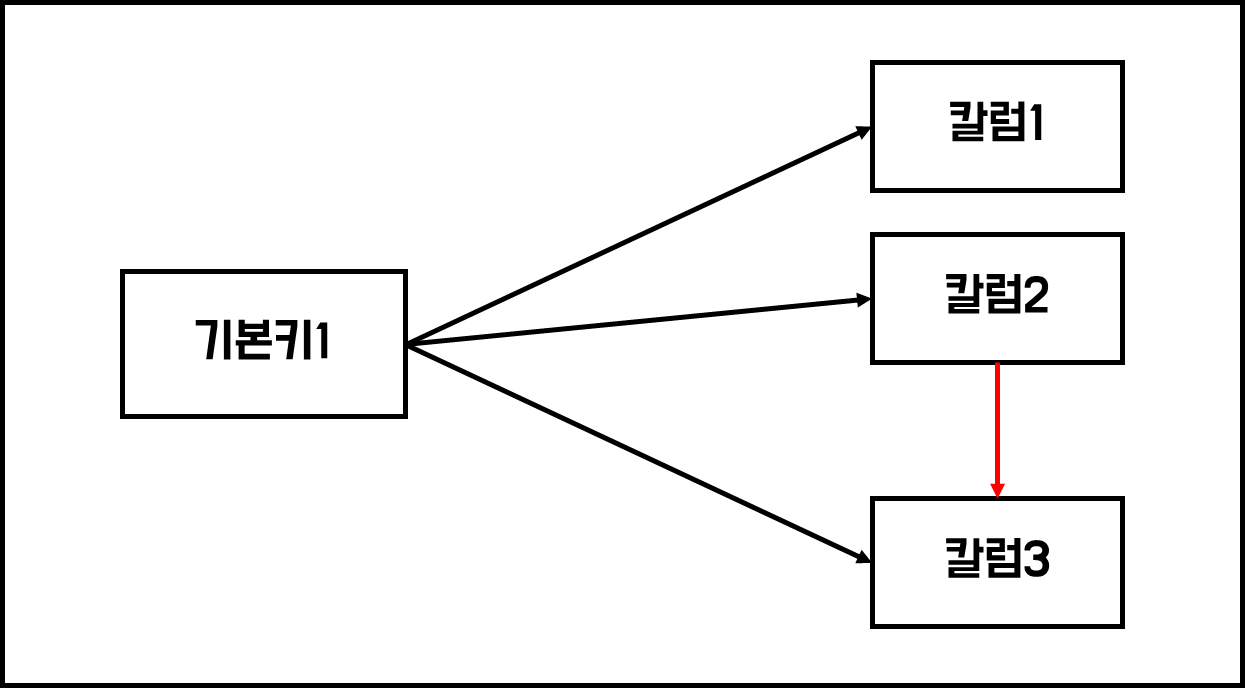
이행 함수 종속성
4. 보이스코드 정규화(BCNF; Boyce-Codd Normal Form)
후보키가 기본키 속성 중 일부에 함수적 종속일 때 다수의 주식별자를 분리함
5. 4차 정규화, 5차 정규화
다치 종속 분리, 결합 종속 분리
🔍 정규화 성능 ⭐
정규화는 입출력 데이터의 양을 줄여 성능을 향상시킴
정규화로 인한 성능 향상
입력/수정/삭제 시 성능은 항상 향상됨
- 유연성 증가 : High Cohesion & Loose Coupling 원칙에 충실해짐
- 재활용 가능성 증가 : 개념이 세분화됨
- 데이터 중복 최소화
정규화로 인한 성능 저하
조회 시 처리 조건에 따라 성능 저하가 발생할 수도 있음,
데이터 조회 시 조인을 유발하여 CPU와 메모리를 많이 사용하게 됨
▶ 반정규화로 해결 가능
▶ 조인이 발생하더라도 인덱스를 사용하여 조인 연산을 수행하면 성능 상 단점이 거의 없고,
정규화를 통해 필요한 인덱스의 수를 줄일 수 있음
▶ 정규화를 통해 소량의 테이블이 생성된다면 성능 상 유리할 수 있음
제1정규형 : 아래의 조건을 만족하는 정규형
-> 모든 속성의 도메인이 원자 값(atomic value)으로만(다중값이 아닌) 구성되어 있으면 제1정규형에 속한다.
제2정규형 : 아래의 조건을 만족하는 정규형
-> 제1정규형에 속하고, 기본키가 아닌 모든 속성이 기본키에 완전 함수 종속되면 제2정규형에 속한다.
제3정규형 : 아래의 조건을 만족하는 정규형
-> 제2정규형에 속하고, 기본키가 아닌 모든 속성이 기본키에 이행적 함수 종속이 되지 않으면 제3정규형에 속한다.
-> 속성간의 함수 종속성이 발생하지 않는 경우
제1정규화 대상 : 제1정규형의 조건을 만족하지 못하는 상태
제2정규화 대상 : 제1정규형이지만 제2정규형의 조건을 만족하지 못하는 상태
제3정규화 대상 : 제2정규형이지만 제3정규형의 조건을 만족하지 못하는 상태
3절. 반정규화와 성능
반정규화(Denormalization) ⭐
정규화된 엔터티, 속성, 관계에 대해 시스템 성능향상과
개발과 운영의 단순화를 위해 중복,통합,분리 등을 수행하는 데이터 모델링의 기법
데이터베이스의 성능 향상을 위해 데이터 중복을 허용하고 조인을 줄이는 것으로,
반정규화를 통해 조회 성능은 좋아지지만
데이터 모델의 유연성은 낮아지며 데이터 무결성이 깨질 위험이 있다 !
Why? 데이터 조회시 디스크 I/O량이 많아 성능 저하 또는 경로가 너무 멀어 JOIN으로 인한 성능 저하 예상 또는 칼럼을 계산하여 읽을 때 성능 저하 예상
반정규화 절차
1. 반정규화 대상 조사
데이터 처리 범위 및 통계성 등 조사
- 범위처리빈도수 조사
- 대량의 범위 처리 조사
- 통계성 프러세스 조사
- 테이블 조인 개수 노사
2. 다른 방법 검토
- 뷰 테이블
- 클러스터링 적용
- 인덱스 조정
- 응용 애플리케이션
3. 반정규화 적용
정규화 수행 후 반정규화 수행
- 테이블 반정규화
- 속성의 반정규화
- 관계의 반정규화
🔍 반정규화 기법 ⭐⭐
1. 테이블 반정규화 : 테이블 병합/분할/추가
• 테이블 병합
- 1:1 관계 테이블 병합
- 1:N 관계 테이블 병합: 많은 데이터 중복 발생
- 슈퍼타입/서브타입 테이블 병합
• 테이블 분할
- 수직분할
- 수평분할
• 테이블 추가
- 중복 테이블 추가 :
업무나 서버가 다를 때 중복 테이블 생성 (원격조인 제거)
- 통계 테이블 추가
- 이력 테이블 추가
- 부분 테이블 추가 :
자주 이용하는 칼럼으로 구성된 테이블 생성
2. 칼럼 반정규화
- 중복 칼럼 추가
- 파생 칼럼 추가: 필요한 값 미리 계산한 칼럼 추가
- 이력 테이블 칼럼 추가
- PK에 의한 칼럼 추가: PK의 종속자를 일반속성으로 생성
- 응용 시스템의 오작동을 위한 칼럼 추가
3. 관계 반정규화
- 중복 관계 추가
- 데이터 무결성 보장 가능
| 구분 | 설명 |
| 반정규화의 대상 분석 |
- 디스크 I/O량이 많아 성능저하 - 경로가 너무 멀어 조인으로 성능저하 - 컬럼을 계산하여 읽을 때 성능 저하 |
| 반정규화 개념 | - 시스템의 성능 향상, 개발 및 운영의 편의성 등을 위해정규화된 데이터 모델을 통합, 중복, 분리하는 과정으로 의도적으로 정규화 원칙을 위배하는 행위 |
| - 반정규화를 수행하면 시스템의 성능이 향상되고 관리 효율성을 증가시키지만 데이터의 일관성 및 정합성이 저하될 수 있다. - 과도한 반정규화는 오히려 성능을 저하시킨다. - 반정규화를 위해서는 사전에 데이터의 일관성과 무결성을 우선으로 할지, 데이터베이스의 성능과 단순화를 우선으로 할지를 결정해야 한다. - 방정규화 방법에는 테이블 통합, 테이블 분할, 중복 테이블 추가, 중복 속성 추가 등이 있다. |
|
| 테이블 통합 | 두 개의 테이블에서 발생하는 프로세스가 동일하게 자주 처리되는 경우, 두 개의 테이블을 이용하여 항상 조회를 수행하는 경우 테이블 통합을 고려한다. |
출처 : https://yunamom.tistory.com/336#google_vignette
4절. 대용량 데이터에 따른 성능
테이블 반정규화 중 테이블 분할 관련
블록: 테이블의 데이터 저장 단위
대량 데이터 발생으로 인한 현상:
블록 I/O 횟수 증가 → 디스크 I/O 가능성 상승
(디스크 I/O 시 성능 저하)
- 로우 체이닝(Row Chaining) : 행 길이가 너무 길어 여러 블록에 걸쳐 저장되는 현상
- 로우 마이그레이션(Row Migration) : 수정된 데이터가 해당 블록이 아닌 다른 블록의 빈 공간에 저장되는 현상
🔍 테이블 분할
1. 반정규화 기법
- 수직분할 : 칼럼 단위로 테이블을 분할하여 I/O를 감소시킴, 너무 많은 수의 칼럼이 있는 경우 사용
-수평분할 : 행 단위로 테이블을 분할하여 I/O를 감소시킴
2. 파티셔닝(Partitioning)
테이블 수평분할 기법,
논리적으로는 하나의 테이블이지만 물리적으로 여러 데이터 파일에 분산 저장,
데이터 조회 범위를 줄여 성능 향상
- Range Partition: 데이터 값의 범위를 기준으로 분할
- List Partition: 특정한 값을 기준으로 분할
- Hash Partition: 해시 함수를 적용하여 분할, DBMS가 알아서 분할 관리, 데이터 위치를 알 수 없음
- Composite Partition: 여러 파티션 기법을 복합적으로 사용하여 분할
※ 파티션 인덱스(Partition Index)
- Global Index, Local Index: 여러 파티션에서 단일 인덱스 사용, 파티션 별로 각자 인덱스 사용
- Prefixed Index, Non-Prefixed Index: 파티션키와 인덱스키 동일, 파티션키와 인덱스키 구분
5절. 데이터베이스 구조와 성능
1. 슈퍼/서브타입 데이터 모델 변환을 통한 성능 향상
- 슈퍼타입/서브타입 데이터 모델
속성을 할당하여 배치하는 수평 분할된 형태의 모델
업무를 구성하는데 데이터의 특징을 공통과 차이점의 특징을 고려하여 효과적으로 표현 가능
공통의 부분을 슈퍼타입으로 모델링하고,
공통으로부터 상속받아 다른 엔터티와 차이가 있는 속성에 대해서 별도의 서브엔터티로 구분
업무의 모습을 정확하게 표현하면서, 물리적인 데이터 모델로 변환을 할 때 선택의 폭을 넓힐 수 있다.
공통 속성은 슈퍼타입으로 모델링하고 차이가 있는 속성은 서브타입으로 구분됨
논리적인 데이터 모델에서 이용
분석단계에서 많이 사용
- 슈퍼/서브타입 변환 기준: 데이터 양 & 트랜잭션 유형
- 슈퍼/서브타입 변환 기술
데이터량이 많이 존재하고, 지속적으로 증가하는 양이 많다면
1) 1:1 타입(OneToOne type)
개별로 처리하는 트랜잭션에 대해 개별 테이블 구성,
슈퍼타입과 서브타입 각각 필요한 속성과 유형에 적합한 데이터만 가지도록 분리하여 1:1 관계를 갖도록 함
2) 슈퍼/서브 타입(Plus type)
슈퍼타입과 서브타입을 공통으로 처리하는 트랜잭션에 대해
슈퍼타입과 서브타입 각각의 테이블 구성
3) All in One 타입(Single type)
전체를 하나로 묶어, 트랜잭션이 발생할 때는 하나의 테이블로 구성
| 1:1 타입 | 슈퍼/서브 타입 | All in One 타입 | |
| 특징 | 개별 테이블 유지 | 슈퍼/서브 타입 테이블 구성 | 단일 테이블 구성 |
| 트랜잭션 유형 | 개별 처리 | 슈퍼/서브 타입 공통 처리 | 일괄 처리 |
| 확장성 | 좋음 (테이블 추가 용이) |
보통 | 나쁨 |
| 조인 성능 | 나쁨 (조인 많이 필요) |
나쁨 (조인 많이 필요) |
좋음 |
| I/O 성능 | 좋음 | 좋음 | 나쁨 (항상 전체 데이터 조회) |
| 관리용이성 | 나쁨 | 나쁨 | 좋음 |

2. 인덱스 특성을 고려한 PK/FK 칼럼 순서 조절을 통한 성능 향상
설계단계말에 칼럼의 순서 조정 필요
테이블에 발생되는 트랜잭션 조회 패턴에 따라 PK/FK 칼럼의 순서 조정 필요
인덱스의 특징은 여러 개의 속성이 하나의 인덱스로 구성되어 있을 때,
앞쪽에 위치한 속성의 값이 비교자로 있어야 인덱스가 좋은 효율을 낼 수 있다.
등호 조건이나 BETWEEN 조건이 걸리는 칼럼을 앞으로 이동
(여러 조건이 있을 경우 등호 조건이 걸리는 칼럼을 선두로 이동)
물리적인 테이블에 FK 제약을 걸어 인덱스를 생성, 순서 고려
(FK - 데이터 조회시 조인의 경로를 제공하는 역할)
6절. 분산 DB 데이터에 따른 성능
분산 DB
- 분산된 DB를 하나의 가상 시스템으로 사용할 수 있도록 한 DB
- 물리적 사이트는 분산되어 있으나 논리적으로 동일한 시스템
- 과거에는 위치 중심이었으나 현재는 업무 필요에 따라 분산 설계
설계 방식
- 상향식: 지역 스키마 작성 후 전역 스키마 작성
- 하향식: 전역 스키마 작성 후 지역사상 스키마 작성
분산 DB의 투명성
- 분할 투명성 : 하나의 논리적 관계가 분할되어 각 단편의 사본이 여러 사이트에 저장됨
- 위치 투명성 : 사용하려는 데이터 저장 장소가 명시되지 않아도 됨
- 지역사상 투명성 : 지역 DBMS와 물리적 DB 사이의 사상이 보장됨
- 중복 투명성 : DB 객체 중복 여부를 몰라도 됨
- 장애 투명성 : 구성요소(DBMS, 컴퓨터)의 장애에 무관하게 트랜잭션의 원자성이 유지됨
- 병행 투명성 : 다수의 트랜잭션을 동시 수행했을 때 결과의 일관성이 유지됨 병렬 아님
분산DB 적용 장점
1) 신뢰성과 가용성
2) 효용성과 융통성
3) 빠른 응답 속도와 통신비용 절감
4) 데이터 가용성과 신뢰성 증가
5) 용량 확장 용이
분산DB 적용 단점
1) 관리 및 통제 어려움
2) 데이터 무결성에 대한 위협
3) 소프트웨어 개발 비용 및 처리 비용 증가
4) 불규칙한 응답 속도
5) 오류의 잠재성 증대
6) 설계, 관리의 복잡성과 비용
분산 DB의 핵심 가치? 데이터 성능 처리
분산 DB 적용 기법
1. 테이블 위치 분산
테이블 구조는 변하지 않고, 테이블이 다른 DB에 중복 생성 X
설계된 테이블의 위치를 각각 다르게 위치
테이블의 위치를 파악할 수 있는 => 도식화된 위치별 DB문서 필요
2. 테이블 분할 분산(Table Fragmentation)
위치만 다른곳에 두는것이 아닌, 각각의 테이블을 쪼개서 분산함
1) 수평분할 - 테이블의 로우 단위
2) 수직분할 - 테이블 칼럼 단위
3. 테이블 복제 분산(Table Replication)
동일한 테이블을 다른 지역이나, 서버에서 동시에 생성하여 관리
원격지 조인을 내부 조인으로 변경하여 성능 향상
1) 부분복제
통합된 테이블을 한군데(본사)에 가지고 있으면서, 각 지사별로는 지사에 해당된 로우를 가지고 있는 형태
여러 테이블에 JOIN이 발생하지 않는 빠른 작업 수행 가능
통계에 좋음
지사에서 데이터 수정이 발생하면 본사로 복제
2) 광역복제
통합된 테이블을 한군데(본사)에 가지고 있으면서, 각 지사에도 본사와 동일한 데이터를 모두 가지고 있는 형태
모든 지사에 있는 데이터와 본사에 있는 데이터가 동일
본사에서 데이터 수정이 발생하면 지사에서 이용
4. 테이블 요약 분산(Table Summarization)
지역간 또는 서버간에 데이터가 비슷하지만, 서로 다른 유형으로 존재하는 경우가 있는데
요약의 방식에따라
1) 분석요약: 사이트 별 요약정보를 본사에서 통합하여 전체 요약정보 산출
2) 통합요약: 사이트 별 정보를 본사에서 통합하여 전체 요약정보 산출
분산 DB 적용 성능 향상
'DB' 카테고리의 다른 글
| [SQLD] 2과목 - 2장 SQL 활용 요약 (2) | 2023.11.14 |
|---|---|
| [SQLD] 2과목 - 1장 SQL 기본 및 활용 요약 (2) | 2023.11.13 |
| [SQLD] 1과목 - 데이터 모델링의 이해 요약 (0) | 2023.11.08 |
| [SQL/ORACLE] SQL 기본 문법 (CREATE, DROP, RENAME) (0) | 2023.06.28 |
| [SQL] 프로시저(Procedure) (1) | 2023.05.15 |


